author: linehk, persdre
时间复杂度和空间复杂度是衡量一个算法效率的重要标准。
基本操作数
同一个算法在不同的计算机上运行的速度会有一定的差别,并且实际运行速度难以在理论上进行计算,实际去测量又比较麻烦,所以我们通常考虑的不是算法运行的实际用时,而是算法运行所需要进行的基本操作的数量。
在普通的计算机上,加减乘除、访问变量(基本数据类型的变量,下同)、给变量赋值等都可以看作基本操作。
对基本操作的计数或是估测可以作为评判算法用时的指标。
时间复杂度
定义
衡量一个算法的快慢,一定要考虑数据规模的大小。所谓数据规模,一般指输入的数字个数、输入中给出的图的点数与边数等等。一般来说,数据规模越大,算法的用时就越长。而在算法竞赛中,我们衡量一个算法的效率时,最重要的不是看它在某个数据规模下的用时,而是看它的用时随数据规模而增长的趋势,即 时间复杂度。
引入
考虑用时随数据规模变化的趋势的主要原因有以下几点:
- 现代计算机每秒可以处理数亿乃至更多次基本运算,因此我们处理的数据规模通常很大。如果算法 A 在规模为 的数据上用时为 而算法 B 在规模为 的数据上用时为 ,在数据规模小于 时算法 B 用时更短,但在一秒钟内算法 A 可以处理数百万规模的数据,而算法 B 只能处理数万规模的数据。在允许算法执行时间更久时,时间复杂度对可处理数据规模的影响就会更加明显,远大于同一数据规模下用时的影响。
- 我们采用基本操作数来表示算法的用时,而不同的基本操作实际用时是不同的,例如加减法的用时远小于除法的用时。计算时间复杂度而忽略不同基本操作之间的区别以及一次基本操作与十次基本操作之间的区别,可以消除基本操作间用时不同的影响。
当然,算法的运行用时并非完全由输入规模决定,而是也与输入的内容相关。所以,时间复杂度又分为几种,例如:
- 最坏时间复杂度,即每个输入规模下用时最长的输入对应的时间复杂度。在算法竞赛中,由于输入可以在给定的数据范围内任意给定,我们为保证算法能够通过某个数据范围内的任何数据,一般考虑最坏时间复杂度。
- 平均(期望)时间复杂度,即每个输入规模下所有可能输入对应用时的平均值的复杂度(随机输入下期望用时的复杂度)。
所谓「用时随数据规模而增长的趋势」是一个模糊的概念,我们需要借助下文所介绍的 渐进符号 来形式化地表示时间复杂度。
渐进符号的定义
渐进符号是函数的阶的规范描述。简单来说,渐进符号忽略了一个函数中增长较慢的部分以及各项的系数(在时间复杂度相关分析中,系数一般被称作「常数」),而保留了可以用来表明该函数增长趋势的重要部分。
一个简单的记忆方法是,含等于(非严格)用大写,不含等于(严格)用小写,相等是 ,小于是 ,大于是 。大 和小 原本是希腊字母 Omicron,由于字形相同,也可以理解为拉丁字母的大 和小 。
在英文中,词根「-micro-」和「-mega-」常用于表示 10 的负六次方(百万分之一)和六次方(百万),也表示「小」和「大」。小和大也是希腊字母 Omicron 和 Omega 常表示的含义。
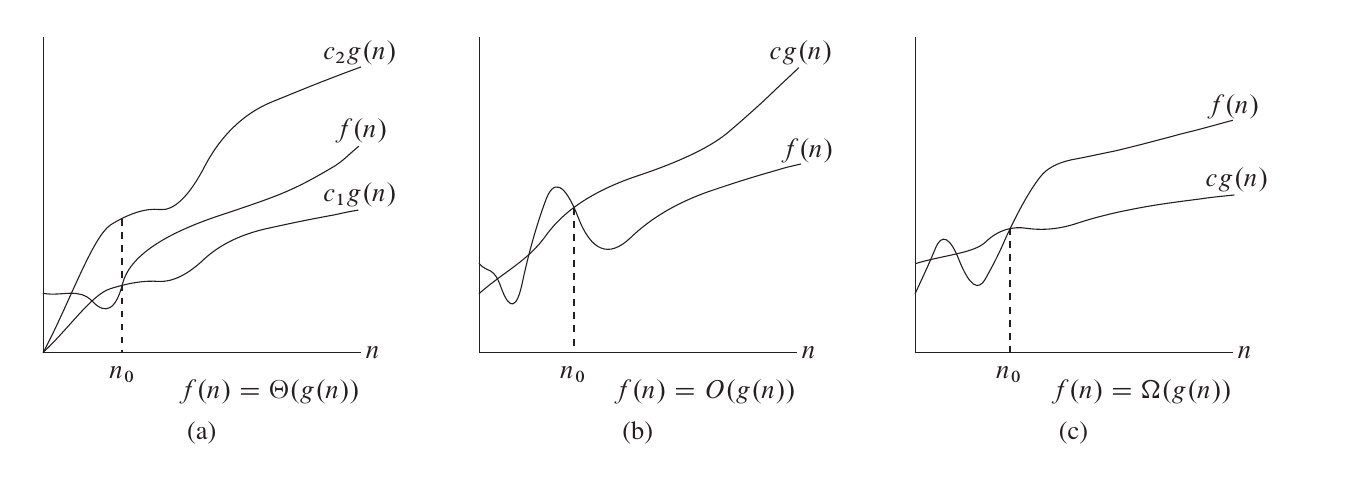
大 Θ 符号
对于函数 和 ,,当且仅当 ,使得 。
也就是说,如果函数 ,那么我们能找到两个正数 使得 被 和 夹在中间。
例如,, 这里的 可以分别是 。,这里的 可以分别是 。
大 O 符号
符号同时给了我们一个函数的上下界,如果只知道一个函数的渐进上界而不知道其渐进下界,可以使用 符号。,当且仅当 ,使得 。
研究时间复杂度时通常会使用 符号,因为我们关注的通常是程序用时的上界,而不关心其用时的下界。
需要注意的是,这里的「上界」和「下界」是对于函数的变化趋势而言的,而不是对算法而言的。算法用时的上界对应的是「最坏时间复杂度」而非大 记号。所以,使用 记号表示最坏时间复杂度是完全可行的,甚至可以说 比 更加精确,而使用 记号的主要原因,一是我们有时只能证明时间复杂度的上界而无法证明其下界(这种情况一般出现在较为复杂的算法以及复杂度分析),二是 在电脑上输入更方便一些。
大 Ω 符号
同样的,我们使用 符号来描述一个函数的渐进下界。,当且仅当 ,使得 。
小 o 符号
如果说 符号相当于小于等于号,那么 符号就相当于小于号。
小 符号大量应用于数学分析中,函数在某点处的泰勒展开式拥有皮亚诺余项,使用小 符号表示严格小于,从而进行等价无穷小的渐进分析。
,当且仅当对于任意给定的正数 ,,使得 。
小 ω 符号
如果说 符号相当于大于等于号,那么 符号就相当于大于号。
,当且仅当对于任意给定的正数 ,,使得 。
常见性质
- 。由换底公式可以得知,任何对数函数无论底数为何,都具有相同的增长率,因此渐进时间复杂度中对数的底数一般省略不写。
简单的时间复杂度计算的例子
for 循环
"C++"
int n, m;
std::cin >> n >> m;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
for (int k = 0; k < m; ++k) {
std::cout << "hello world\n";
}
}
}"Python"
n = int(input())
m = int(input())
for i in range(0, n):
for j in range(0, n):
for k in range(0, m):
print("hello world")"Java"
int n, m;
n = input.nextInt();
m = input.nextInt();
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
for (int k = 0; k < m; ++k) {
System.out.println("hello world");
}
}
}如果以输入的数值 和 的大小作为数据规模,则上面这段代码的时间复杂度为 。
DFS
在对一张 个点 条边的图进行 DFS 时,由于每个节点和每条边都只会被访问常数次,复杂度为 。
哪些量是常量?
当我们要进行若干次操作时,如何判断这若干次操作是否影响时间复杂度呢?例如:
"C++"
const int N = 100000;
for (int i = 0; i < N; ++i) {
std::cout << "hello world\n";
}"Python"
N = 100000
for i in range(0, N):
print("hello world")"Java"
final int N = 100000;
for (int i = 0; i < N; ++i) {
System.out.println("hello world");
}如果 的大小不被看作输入规模,那么这段代码的时间复杂度就是 。
进行时间复杂度计算时,哪些变量被视作输入规模是很重要的,而所有和输入规模无关的量都被视作常量,计算复杂度时可当作 来处理。
需要注意的是,在进行时间复杂度相关的理论性讨论时,「算法能够解决任何规模的问题」是一个基本假设(当然,在实际中,由于时间和存储空间有限,无法解决规模过大的问题)。因此,能在常量时间内解决数据规模有限的问题(例如,对于数据范围内的每个可能输入预先计算出答案)并不能使一个算法的时间复杂度变为 。
主定理 (Master Theorem)
我们可以使用 Master Theorem 来快速求得关于递归算法的复杂度。
Master Theorem 递推关系式如下
那么
需要注意的是,这里的第二种情况还需要满足 regularity condition, 即 ,for some constant and sufficiently large 。
证明思路是是将规模为 的问题,分解为 个规模为 的问题,然后依次合并,直到合并到最高层。每一次合并子问题,都需要花费 的时间。
??? note "证明"
依据上文提到的证明思路,具体证明过程如下
对于第 $0$ 层(最高层),合并子问题需要花费 $f(n)$ 的时间
对于第 $1$ 层(第一次划分出来的子问题),共有 $a$ 个子问题,每个子问题合并需要花费 $f\left(\frac{n}{b}\right)$ 的时间,所以合并总共要花费 $a f\left(\frac{n}{b}\right)$ 的时间。
层层递推,我们可以写出类推树如下:
这棵树的高度为 ${\log_b n}$,共有 $n^{\log_b a}$ 个叶子,从而 $T(n) = \Theta(n^{\log_b a}) + g(n)$,其中 $g(n) = \sum_{j = 0}^{\log_{b}{n - 1}} a^{j} f(n / b^{j})$。
针对于第一种情况:$f(n) = O(n^{\log_b a-\epsilon})$,因此 $g(n) = O(n^{\log_b a})$。
对于第二种情况而言:首先 $g(n) = \Omega(f(n))$,又因为 $a f(\dfrac{n}{b}) \leq c f(n)$,只要 $c$ 的取值是一个足够小的正数,且 $n$ 的取值足够大,因此可以推导出:$g(n) = O(f(n)$)。两侧夹逼可以得出,$g(n) = \Theta(f(n))$。
而对于第三种情况:$f(n) = \Theta(n^{\log_b a})$,因此 $g(n) = O(n^{\log_b a} {\log n})$。$T(n)$ 的结果可在 $g(n)$ 得出后显然得到。
下面举几个例子来说明主定理如何使用。
,那么 ,那么 可以取值在 之间,从而满足第一种情况,所以 。
,那么 ,那么 可以取值在 之间,从而满足第二种情况,所以 。
,那么 ,那么 可以取值为 ,从而满足第三种情况,所以 。
,那么 ,那么 可以取值为 ,从而满足第三种情况,所以 。
均摊复杂度
算法往往是会对内存中的数据进行修改的,而同一个算法的多次执行,就会通过对数据的修改而互相影响。
例如快速排序中的「按大小分类」操作,单次执行的最坏时间复杂度,看似是 的,但是由于快排的分治过程,先前的「分类」操作每次都减小了数组长度,所以实际的总复杂度 ,分摊在每一次「分类」操作上,是 。
多次操作的总复杂度除以操作次数,就是这种操作的 均摊复杂度。
势能分析
势能分析,是一种求均摊复杂度上界的方法。
求均摊复杂度,关键是表达出先前操作对当前操作的影响。势能分析用一个函数来表达此种影响。
定义「状态」:即某一时刻的所有数据。在快排的例子中,一个「状态」就是当前过程需要排序的下标区间
定义「初始状态」:即未进行任何操作时的状态。在快排的例子中,「初始状态」就是整个数组
假设存在从状态到数的函数 ,且对于任何状态 ,,则有以下推论:
设 为从 开始连续做 次操作所得的状态序列, 为第 次操作的时间开销。
记 ,则 次操作的总时间花销为
(正负相消,证明显然)
又因为 ,所以有
因此,若 ,则 是均摊复杂度的一个上界。
势能分析在实际应用中有很多技巧,在此不详细展开。
空间复杂度
类似地,算法所使用的空间随输入规模变化的趋势可以用 空间复杂度 来衡量。
计算复杂性
本文主要从算法分析的角度对复杂度进行了介绍,如果有兴趣的话可以在 计算复杂性 进行更深入的了解。